

In a previous blog post we looked at a couple of algorithms from the C++ standard library and how their performance measured up when used in an audio development context like we do in building ELK. The algorithms under the microscope were std::minmax_elements, std::abs and std::clamp. We also looked at some resulting assembly code and how you could write C++ code to give the compiler the best chances of optimising the code. In this follow up part we will dive into another two algorithms designed to modernise C++ and replace legacy functions.
Before C++11 the most common way to fill or copy a larger block of contiguous memory, for instance when zeroing an audio buffer or copying one audio buffer to another, was via the posix functions memcpy and memset respectively. Those functions have, together with memmove, strcpy, and a few more, been around since the dawn of C and are part of its standard library. Anyone with some experience developing in C have likely used them extensively. They are available in C++ by including <cstring> in your code.
These functions have some issues that potentially make them problematic in modern C++. First, they only deal with memory on a byte level and are completely oblivious to the objects represented by the underlying memory. Objects that need copy constructors or move constructors in order to do, for instance deep copies of object members, cannot be safely copied with memcpy. In fact the only objects that are safe to copy with memcpy are native types and those that meet the trivially copyable criteria. Unfortunately the latter condition is not compatible with main C++ concepts such as virtual inheritance.
Even if objects are safe to copy, memcpy needs to be passed the size of the object(s), in bytes, which is a common source of error that can lead to buffer over/underruns or object slicing. I think most developers can recall situations where there has been confusion over whether a size or length argument referred to the number of elements or to the number of bytes in the data. I definitely can and the resulting bugs can be tricky to track down.
Another issue with memset, is that it only takes an integer argument, further truncated to the size of a byte, for the value. Meaning that for floating point buffers, memset can only effectively be used to zero out the buffer, not to fill the buffer with arbitrary floating point values. Though setting a buffer to zero is probably the most common use case.
std::copy and std::fill are the modern replacements for these functions. They are based on templates and hence can understand the underlying type, invoke constructors or destructors if necessary, and will naturally align to object boundaries if copying a range. They also take iterators as arguments, which means that if you write custom containers, they can be used with std::fill or std::copy as long as the begin() and end() functions of your containers are correctly implemented.
The modern C++ replacements are type-safe, type-aware, less bug-prone, and more powerful that their old C counterparts. Sounds fantastic in every way, doesn’t it? Though just as in the previous post, an important question for us audio developers is whether all these features come with a runtime performance penalty or not.
So let’s find out! First let’s look at comparing std::copy with memset and with a very simple implementation of our own where we copy sample by sample and leave all optimisations up to the compiler. As before we will use std::array for our audio buffer type:
using AudioBuffer = std::array<float, AUDIO_BUFFER_SIZE>;
void alg_copy(const AudioBuffer& source, AudioBuffer& dest)
{
std::copy(source.begin(), source.end(), dest.begin());
}
void memcpy_copy(const AudioBuffer& source, AudioBuffer& dest)
{
memcpy(dest.data(), source.data(), source.size()*sizeof(float));
}
void custom_copy(const AudioBuffer& source, AudioBuffer& dest)
{
for (unsigned int i = 0; i < source.size(); ++i)
{
dest[i] = source[i];
}
}
As before, we compile with 2 different compilers, GCC 8.1 and Clang 6. Both versions were released a little over a year ago. And then we run our test program on one of our Rocket development boards.
In the first post we ran the tests with 0%, 1% and 50% of the sample values outside of the range [-1, 1] in order to see if the performance had a dependency towards the data. As copying data does not depend on the data, we will only run it once with all values within the [-1, 1] range. Instead we will look at performance for different buffer sizes.
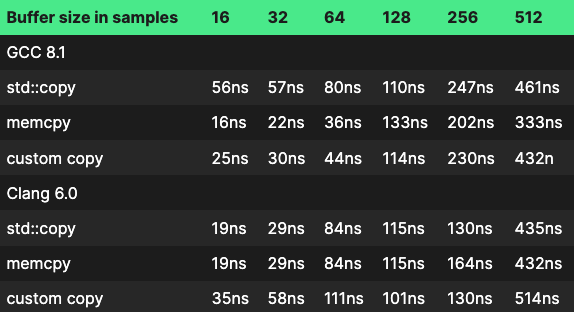
So results are a mixed bag. For small buffer sizes, the most efficient is still memcpy, but for larger buffer sizes it starts to make less of a difference.
For both memcpy and std::copy there seems to be a cutoff point where the call is transformed from an unrolled copy loop into a function call. A function call does have some overhead and a potential source of cache misses, though if every copy operation were to be inlined, we would end up with very bloated binaries. So the tradeoff is understandable. Where this cutoff point is placed differs between the compilers though. GCC translates every calls to std::copy with a call to memmove regardless of the buffer size, while Clang only does it for buffer sizes of 64 or more, same with memcpy. GCC does only seem to translate memcpy to a function call if the size to copy is not constant.
There is also a cutoff point where the compiler stops unrolling the loop. For GCC we see that for buffer sizes of 128 and up, the loop is vectorised into SIMD instructions, but not unrolled. The extra overhead of a branch instruction every iteration it probably what makes the performance drop here.
It’s also interesting to note that there is no clear winner between GCC and Clang, but they differ considerably in performance. So what is really going on under the hood here? We can use the amazing Compiler Explorer tool to see what assembly code is generated by the compilers. Here is an interactive link to the code in question https://godbolt.org/z/WQmnrr. You can change the compiler version or buffer size yourself and see the resulting assembly code.
First we look at the GCC case with a buffer size of 32 elements. It’s interesting to note that we see 3 different ways of doing the same thing. std::copy compiles to a call to memmove. Memmove does the same as memcpy with the exception that it also works with overlapping memory.
alg_copy(std::array<float, 32ul> const&,
std::array<float, 32ul>&):
mov rax, rdi
mov edx, 128
mov rdi, rsi
mov rsi, rax
jmp memmove
Interestingly enough, the memcpy version does not compile into a function call. It compiles into an unrolled loop using the movqdu instruction – Move Unaligned Double Quadword.
memcpy_copy(std::array<float, 32ul> const&,
std::array<float, 32ul>&):
movdqu xmm0, XMMWORD PTR [rdi]
movdqu XMMWORD PTR [rsi], xmm0
movdqu xmm1, XMMWORD PTR [rdi+16]
movdqu XMMWORD PTR [rsi+16], xmm1
movdqu xmm2, XMMWORD PTR [rdi+32]
movdqu XMMWORD PTR [rsi+32], xmm2
movdqu xmm3, XMMWORD PTR [rdi+48]
...
While the custom copy version is much longer and I’m not printing the entire assembly here. But it essentially copies data using the movss – Move Scalar Single-Precision Floating-Point instruction until it gets to an address aligned to 16 bytes – the size of a vector register on the CPU we have compiled for. Then it switches to a combination of movaps and movups, vectorised move instructions that use aligned and un-aligned memory access respectively. Interestingly enough, the function reads to a register using aligned access (movaps), then copies using an unaligned instruction (movups).
The Intel Atom CPU we’re using for the Rocket board supports SSE4 vector instructions with 128 bit registers – enough to process 4 single precision floats simultaneously.
custom_copy(std::array<float, 32ul> const&,
std::array<float, 32ul>&):
...
movss xmm0, DWORD PTR [rdi+4]
cmp edx, 2
movss DWORD PTR [rsi+4], xmm0
je .L15
movss xmm0, DWORD PTR [rdi+8]
mov r10d, 29
movss DWORD PTR [rsi+8], xmm0
...
movaps xmm1, XMMWORD PTR [rcx]
mov edx, r9d
movups XMMWORD PTR [rax], xmm1
movaps xmm2, XMMWORD PTR [rcx+16]
movups XMMWORD PTR [rax+16], xmm2
movaps xmm3, XMMWORD PTR [rcx+32]
movups XMMWORD PTR [rax+32], xmm3
movaps xmm4, XMMWORD PTR [rcx+48]
...
If we take a look at what Clang generates, we see that it generates almost exactly the same code for both std::copy and memcpy. Interestingly enough, in contrast to GCC that tries to copy element by element first and then aligned vectorised copy. Clang uses unaligned copy instructions all the way.
alg_copy(std::array<float, 32ul> const&,
std::array<float, 32ul>&)
movups xmm0, xmmword ptr [rdi]
movups xmm1, xmmword ptr [rdi + 16]
movups xmm2, xmmword ptr [rdi + 32]
movups xmm3, xmmword ptr [rdi + 48]
…
movups xmmword ptr [rsi + 112], xmm7
movups xmmword ptr [rsi + 96], xmm6
movups xmmword ptr [rsi + 80], xmm5
movups xmmword ptr [rsi + 64], xmm4
…
memcpy_copy(std::array<float, 32ul> const&,
std::array<float, 32ul>&)
movups xmm0, xmmword ptr [rdi + 112]
movups xmmword ptr [rsi + 112], xmm0
movups xmm0, xmmword ptr [rdi + 96]
movups xmmword ptr [rsi + 96], xmm0
movups xmm0, xmmword ptr [rdi + 80]
movups xmmword ptr [rsi + 80], xmm0
movups xmm0, xmmword ptr [rdi + 64]
movups xmmword ptr [rsi + 64], xmm0
...
Another interesting part is that for the custom case for buffer sizes less than 64, Clang unrolls the loop but doesn’t vectorise. Instead, it does the copying with scalar instructions, element by element with a mov instruction to move a single 4 byte word. With buffer sizes of 64 or more, it does vectorise however. Why clang fails to vectorise for small buffer sizes is a mystery however.
custom_copy(std::array<float, 32ul> const&,
std::array<float, 32ul>&)
mov eax, dword ptr [rdi]
mov dword ptr [rsi], eax
mov eax, dword ptr [rdi + 4]
mov dword ptr [rsi + 4], eax
mov eax, dword ptr [rdi + 8]
mov dword ptr [rsi + 8], eax
...
Another thing to note is that both compilers do register renaming, a technique to use a different register for every instruction in order to avoid pipeline stalls. The first instruction stores the data temporality in register 1, and the second in register 2, etc. This improves parallelisation, but can also be done internally in the CPU if not done explicitly in the code.
Another interesting thing is that GCC prefers to do the bulk of operations with aligned vector instruction, and generating “lead in” and “lead out” sections the handle the remainder, if the data is not aligned to a vector register size binary (16 bytes in case of SSE). While Clang prefers to use unaligned instructions that can work on unaligned data. On this particular architecture, the unaligned version looks like the winner, but this is probably highly CPU dependant. Historically unaligned accesses have been faster but cpu manufacturers have been working to make unaligned memory accesses faster in recent years. In the GCC version of the custom_copy(), the aligned access is probably a failed optimisation, as the reads are aligned, but the writes are still unaligned and will likely be the bottleneck.
Secondly we do the same with std::fill, memset, and the most simple fill implementation we could write.
void alg_fill(AudioBuffer& buffer, float value)
{
std::fill(buffer.begin(), buffer.end(), value);
}
void memset_fill(AudioBuffer& buffer, int value)
{
memset(buffer.data(), value, buffer.size() * sizeof(float));
}
void custom_fill(AudioBuffer& buffer, float value)
{
for (auto& a : buffer)
{
a = value;
}
}
Results:
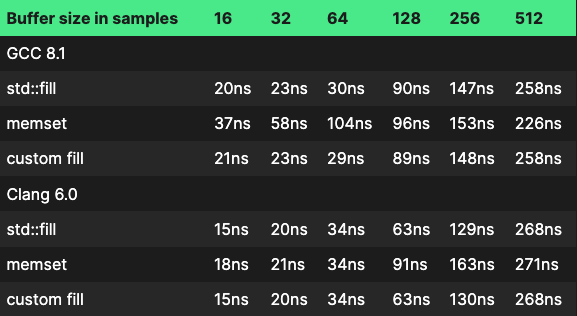
Again, we see a mixed bag of results. Though the differences are smaller than for std::copy vs memcpy. For the entire assembly code, see https://godbolt.org/z/WSGWlT.
As with std::copy, we see that for std::fill and for the custom case, GCC generates lead in/lead out sections in the beginning and end, and then does the bulk of operations using aligned move instructions. Clang on the other hand prefers to keep things simple by only using unaligned instructions. It might very well be that for 32 samples or less, the overhead of the lead in/out sections takes more time than you gain with the aligned instructions, but for 64 samples the aligned instructions are fast enough to make up for this and make the whole function run faster.
For buffer sizes of 128 and above, gcc stops unrolling the loop, which is probably why performance drops against clang here.
Clang:
alg_fill(std::array<float, 32ul>&, float):
shufps xmm0, xmm0, 0 # xmm0 = xmm0[0,0,0,0]
movups xmmword ptr [rdi], xmm0
movups xmmword ptr [rdi + 16], xmm0
movups xmmword ptr [rdi + 32], xmm0
movups xmmword ptr [rdi + 48], xmm0
movups xmmword ptr [rdi + 64], xmm0
movups xmmword ptr [rdi + 80], xmm0
movups xmmword ptr [rdi + 96], xmm0
movups xmmword ptr [rdi + 112], xmm0
ret
GCC:
alg_fill(std::array<float, 32ul>&, float):
mov rax, rdi
mov rsi, rdi
shr rax, 2
mov r8d, 32
neg rax
and eax, 3
je .L2
...
movaps XMMWORD PTR [rdx], xmm1
cmp rax, 7
movaps XMMWORD PTR [rdx+16], xmm1
movaps XMMWORD PTR [rdx+32], xmm1
movaps XMMWORD PTR [rdx+48], xmm1
movaps XMMWORD PTR [rdx+64], xmm1
movaps XMMWORD PTR [rdx+80], xmm1
movaps XMMWORD PTR [rdx+96], xmm1
je .L4
movaps XMMWORD PTR [rdx+112], xmm1
...
ret
Another thing to note is that Clang only calls memset for buffer sizes of 128 and up, while Gcc never calls memset at runtime, it always inlines the function. The only way to make gcc actually call memset was to make the size of the memory block copied a runtime variable.
If you want to test the performance yourself or play around with the variables, you are welcome to download all the code used in the articles here and test it on your own machine: https://github.com/noizebox/std-algorithm-for-audio
As in the previous post, there is unfortunately no crystal clear conclusion to make, apart from profile and test the specific use case you have. Though std::fill does seem to do at least as good as memset though, and in many cases better.
One thing that is clear is that calls to memset or memcpy will not always result in a function call in the end, the compiler might decide to inline the code instead depending on the size of the memory copied and whether the size can be determined during compilation. Gcc always translates std::copy to a call to memmove, which for small buffer sizes is not optimal.
It is important to retain a sense of proportions in all of this though. And to remind ourselves that while we are chasing a few nanoseconds here and there, std::copy and std::fill have many other advantages such as type safety and type awareness and should be the first choice in almost every situation as it will lead to better and safer code. It is only deep down in the lowest parts of our dsp functions were the performance gains of a few tens of nano seconds could actually be relevant.
I hope you have found this post interesting and useful. If you have any comments or questions on the content, please feel free to leave a comment below or write us at tech@mindmusiclabs.com

